Compressing Earth Embeddings, pt. 3 – DeltaBit
In our TerraBit post last time, we binary-quantized the global Clay v1.5 embeddings down to 128 bytes per patch and served 50M of them from static object storage — implementing planetary scale retrieval entirely in the browser. The first post in the series, Compressing Earth Embeddings, set up the underlying claim: int8 quantization is statistically free across every model and dataset we tested, and PCA can strip most dimensions without meaningful accuracy loss.
Those posts were about patch embeddings — one vector per Sentinel-2 chip/patch/image, queried like a vector database.
This is the other half of the story: pixel embeddings. Dense prediction tasks, like change detection, segmentation, and anomaly maps, need a vector at every pixel and to be available everywhere the user is looking. A single Sentinel-2 tile at 10m resolution holds ~120 million pixels; even at AlphaEarth’s (AEF) native 64-dimensional int8 (currently the most compact per-pixel earth embedding released) that’s ~7.7 GB per scene, and wider float32 models like DINOv3 ViT-L are ~60× larger per pixel. However, the same compression that made TerraBit possible should let us serve per-pixel embeddings as XYZ map tiles and train models on them in the browser. This post tests this idea on change detection.
We built a demo called DeltaBit. Zoom in on Seattle, click a few dozen change/no-change pixels on the map, and a logistic regression trains (in the browser, on just those clicks — no server round-trip) and runs inference across every visible tile in milliseconds. Tiles are int8-quantized PCA-8 difference embeddings — 8 bytes per pixel — served as standard {z}/{x}/{y}.tif GeoTIFFs from a web server.
Study area and data
We used the AEF Mosaic — a global Zarr v3 archive of AlphaEarth embedding fields on S3, built by Jeff Albrecht in collaboration with Taylor Geospatial, with annual composites from 2017–2025. Each pixel is a 64-dimensional signed int8 vector aligned to the Sentinel-2 10m grid.
| Property | Value |
|---|---|
| Sentinel-2 MGRS tile | T10TET (Seattle metro) |
| Comparison years | 2020 vs 2024 |
| Raster | 11,099 × 16,337 pixels (181.3 M pixels) |
| Embedding | 64-d int8 per pixel, AEF Mosaic |
The per-pixel temporal difference (emb_2024 − emb_2020) gives a 64-d float32 feature vector at every location. Pixels where the surface didn’t change cluster near zero; changed pixels project to non-zero directions in that 64-d space, and the experiment below tests how well a linear model can read those directions back out.
Compressing the difference vectors
Our working hypothesis from pt. 1 is that most of the nominal dimensions in an earth embedding are redundant — the intrinsic dimensionality is much lower — and PCA is the tool we use to collapse down to a compact basis. DeltaBit is a test of whether that same idea holds for difference vectors, where we stand to gain the most from it. We fit PCA on a 1-in-1000 subsample of the full raster diff (~181K pixels) and looked at how variance is distributed across the 64 components.
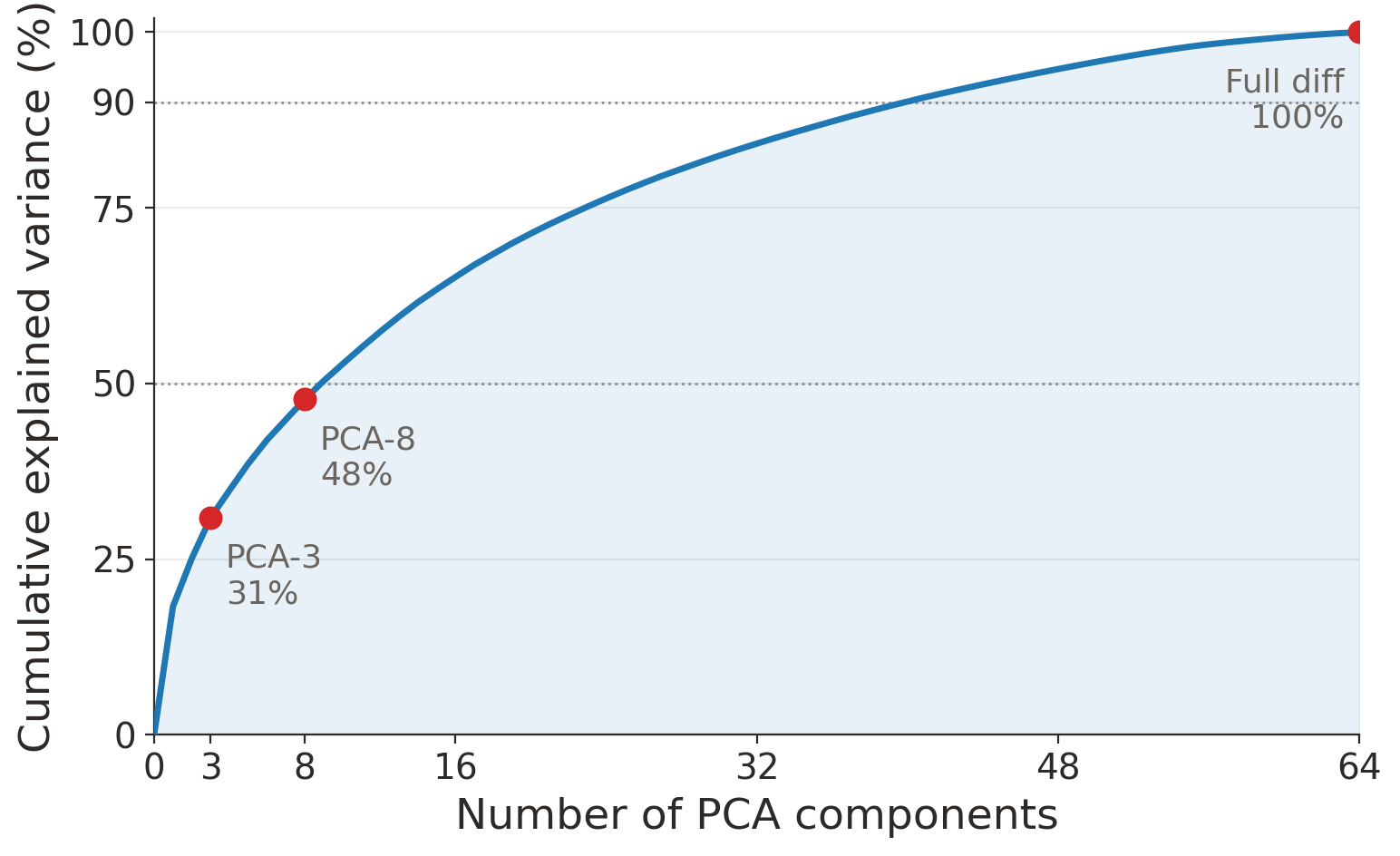
Cumulative explained variance of PCA fit on the full Seattle 2020→2024 AEF embedding diff. No single component dominates: PC1 captures 18%, 8 components reach 48%, and 40 components are needed for 90%.
Variance is broadly distributed. PC1 captures only 18.3%; you need 9 components to cross 50% and 40 to cross 90%. This is much flatter than the static-embedding case from our compression post, where AEF reaches 80% variance in 8 dimensions. One hypothesis: differencing partly cancels the dominant scene-level modes — land cover, broad vegetation state — that two nearby years share, and what’s left is a more isotropic mix of higher-frequency change signals and embedding noise. We haven’t validated that directly.
PCA-8 retains less than half the variance. That’s a strong test of whether per-pixel change detection survives aggressive compression. Variance is not the same as predictive signal, but if the model needs the long tail, PCA-8 will lose it.
Change detection with pixel supervision
We labeled 336 pixels by hand — 190 change, 146 no-change — using a side-by-side Sentinel-2 swipe of 2020 vs 2024 true-color imagery. At each labeled pixel we sample the 2020 and 2024 embeddings, compute the diff, and project it through three feature pipelines:
- PCA-3 — first 3 principal components (3-d)
- PCA-8 — first 8 principal components (8-d)
- Full diff — the raw 64-d difference, no PCA
For each, we run logistic regression with 10-fold stratified nested cross-validation: an outer 10-fold for unbiased performance estimation, and an inner 5-fold sweep to pick the regularization strength on F1.1
| Feature set | Accuracy | F1 | Precision | Recall |
|---|---|---|---|---|
| PCA-3 (3-d) | 0.90 ± 0.05 | 0.90 ± 0.05 | 0.97 ± 0.04 | 0.85 ± 0.10 |
| PCA-8 (8-d) | 0.96 ± 0.04 | 0.96 ± 0.04 | 0.98 ± 0.03 | 0.94 ± 0.06 |
| Full diff (64-d) | 0.99 ± 0.02 | 0.99 ± 0.01 | 1.00 ± 0.00 | 0.98 ± 0.03 |
10-fold stratified CV on 336 hand-labeled pixels. Inner 5-fold for C selection on F1. Mean ± std across outer folds. Bolds mark column-wise bests on the metrics that drive the comparison; precision saturates near 1.0 across all three feature sets, so it isn’t a useful tiebreaker.
A few things worth pulling out:
PCA-8 is the practical sweet spot. 96% F1 with 8 features is more than enough for an interactive viewer. The demo’s compressed tiles — int8-quantized PCA-8 at 8 bytes per pixel — are 8× smaller than the source AEF int8 embeddings that went in (and 32× smaller than the raw float32 diff the CV ran on), at essentially no cost to what you can do on top of them. The CV here is on float32 PCA-8; pt1 already showed int8 quantization on top of PCA is statistically free, so the in-browser tiles inherit the same number.
Precision is consistently ≥0.97. The model rarely flags no-change pixels as change. The error mode is missed changes: recall climbs from 0.85 (PCA-3) to 0.94 (PCA-8) as feature dimensionality grows.
PCA-3 is useful even without a model. The first three components already reach 90% F1 on a linear probe, which means the change signal is concentrated enough that just looking at the top 3 PCs — mapped directly to R/G/B — surfaces changed pixels by eye. DeltaBit exposes this as an overlay toggle at the top of the labeling panel, and changed areas jump out with no training at all:
The middle row is what DeltaBit serves. The same logistic regression evaluated above gets re-fit in the browser on whatever you click, in a few hundred milliseconds. 8 bytes per pixel also means the entire Seattle scene fits in 2.60 GiB of XYZ tiles at zoom levels 8–14. The browser fetches GeoTIFFs on demand with GeoTIFF.js, caches them per tile key, and runs a WebGPU dot product over each tile to score every pixel.
What 96% F1 actually looks like, on a rural area south of Seattle:



Three views of the same crop: click a tab or press ←/→ to flip between the 2020 and 2024 Sentinel-2 true-color panels and the trained model’s change prediction. Several parcels were cleared between the two dates and the model — a logistic regression fit in the browser on a few dozen clicks — recovers them as red pixels in the third panel.
The same flow, end to end in the viewer — 14 clicks is enough to stand up a deforestation detector on this area:
We zoom into a rural patch south of Seattle, place 8 change clicks on cleared parcels and 6 no-change clicks on untouched forest, hit Train, and switch to the heatmap view. The model generalizes cleanly across the local area, lighting up the other clearings we didn’t label.
One thing we noticed — and which in retrospect had to work this way: the lower zoom levels in the pyramid are built by 2×2-averaging the int8 PCA-8 tiles directly, and the same trained linear model produces coherent change predictions at those zooms. Zoom out in the viewer and cleared parcels and construction still light up. The whole pipeline is linear — differencing, PCA, and the model’s pre-sigmoid logit all commute with averaging — so the logit of an averaged tile equals the mean of its four child logits, modulo a bit of int8 rounding. The sigmoid mildly distorts that on the probability side, but not enough to blur the signal. It’s a free side effect of keeping every stage before the classifier linear.
You can try this for yourself — open DeltaBit, pick a spot in the Seattle metro, click a dozen change and no-change pixels, and see the prediction layer update across the visible map. Arrow keys / scroll to fly around; the same tiles get reused at every zoom level.
Limitations
Single scene pair. One Sentinel-2 tile, one year pair. We haven’t tested other sensors, resolutions, or temporal baselines.
Narrow slice of change types. The 336 labeled pixels are dominated by deforestation and urban changes — new construction, road work, cleared parcels — because that’s what’s conspicuous in a 2020→2024 side-by-side over Seattle. Agricultural cycles, flooding, fires, snow and ice, and seasonal vegetation shifts are barely represented, so the CV scores don’t speak to how well a linear model separates those change modes from each other (or from no-change).
Tested on AEF only. The recipe is model-agnostic — PCA + int8 + XYZ tiles works on any per-pixel embedding — but we only ran the experiment on AEF. We picked AEF because a global Zarr store already exists and we had code to pull from it; the bottleneck was data access, not the pipeline. That friction is decreasing fast. As more per-pixel embedding products ship as global mega-Zarrs, COGs, or APIs, running the same PCA(8) + int8 + XYZ recipe against them becomes a configuration change rather than a project. A global change-detection app over any of those sources isn’t inconceivable — just unbuilt.
Takeaways
PCA-8 + int8 is the sweet spot for interactive change detection. A full Sentinel-2 scene’s worth of change embeddings fits in a few GB of tiles — small enough to stream to a browser and run dense inference on the GPU without any server involvement, while still matching what a model trained on the raw embeddings can do. Concretely: 8 bytes per pixel gets 96% F1, which is 8× smaller than the source AEF int8 embeddings (32× smaller than the float32 diff the CV ran on). The recipe is model-agnostic: DINOv3, OlmoEarth, Tessera, or any other per-pixel embedding from pt. 1 would slot in the same way.
Difference embeddings compress less neatly than static ones — and it doesn’t matter. Subtracting two years of embeddings produces a messier, higher-dimensional signal than either year alone, but enough of what matters for change detection survives the first handful of components. Static AEF reaches 80% variance in 8 dims; the 2020→2024 diff needs 40 components to clear 90%, and PCA-8 only retains 48%. Despite that, PCA-8 already hits 96% F1 on the labeled set — variance isn’t the same as predictive signal, and 8 bytes per pixel is the right place to draw the line for an interactive viewer.
Linear is enough. The embeddings are doing the heavy lifting, so a simple classifier on top is all you need — which, as a bonus, is trivially fast to train and run on the GPU in the browser. Logistic regression on 8 features hits 96% F1; nothing fancier is needed for the webapp to feel like a useful tool.
Links: DeltaBit demo · pt. 1: Compressing Earth Embeddings · pt. 2: TerraBit
Footnotes
Slightly interesting side note: the median selected
C(inverse regularization strength) decreases as the feature set grows — PCA-3 wants weaker regularization than PCA-8, which wants weaker than the full 64-d diff. With fewer features the model needs more freedom to fit the limited signal; with 64 features, regularization keeps it honest.↩︎
Citation
@online{robinson2026,
author = {Robinson, Caleb and Corley, Isaac},
title = {Compressing {Earth} {Embeddings,} Pt. 3 -\/- {DeltaBit}},
date = {2026-04-15},
url = {https://geospatialml.com/posts/change-detection/},
langid = {en}
}